Karpathy 用三文件夹做了一个知识库,我把它改造成了多 Agent 协作版
省流版:上周,Karpathy 发了一条推文,说他现在花在 LLM 上的 token,大部分不是在写代码,而是在整理知识。
然后他分享了一个叫"LLM Wiki"的方法——用三个文件夹 + 一个配置文件,搭一个让 LLM 帮你管理知识的系统。文章的结尾,我把我的系统开源了。
我看到的时候,第一反应是——这不就是我们一直在折腾的事吗?
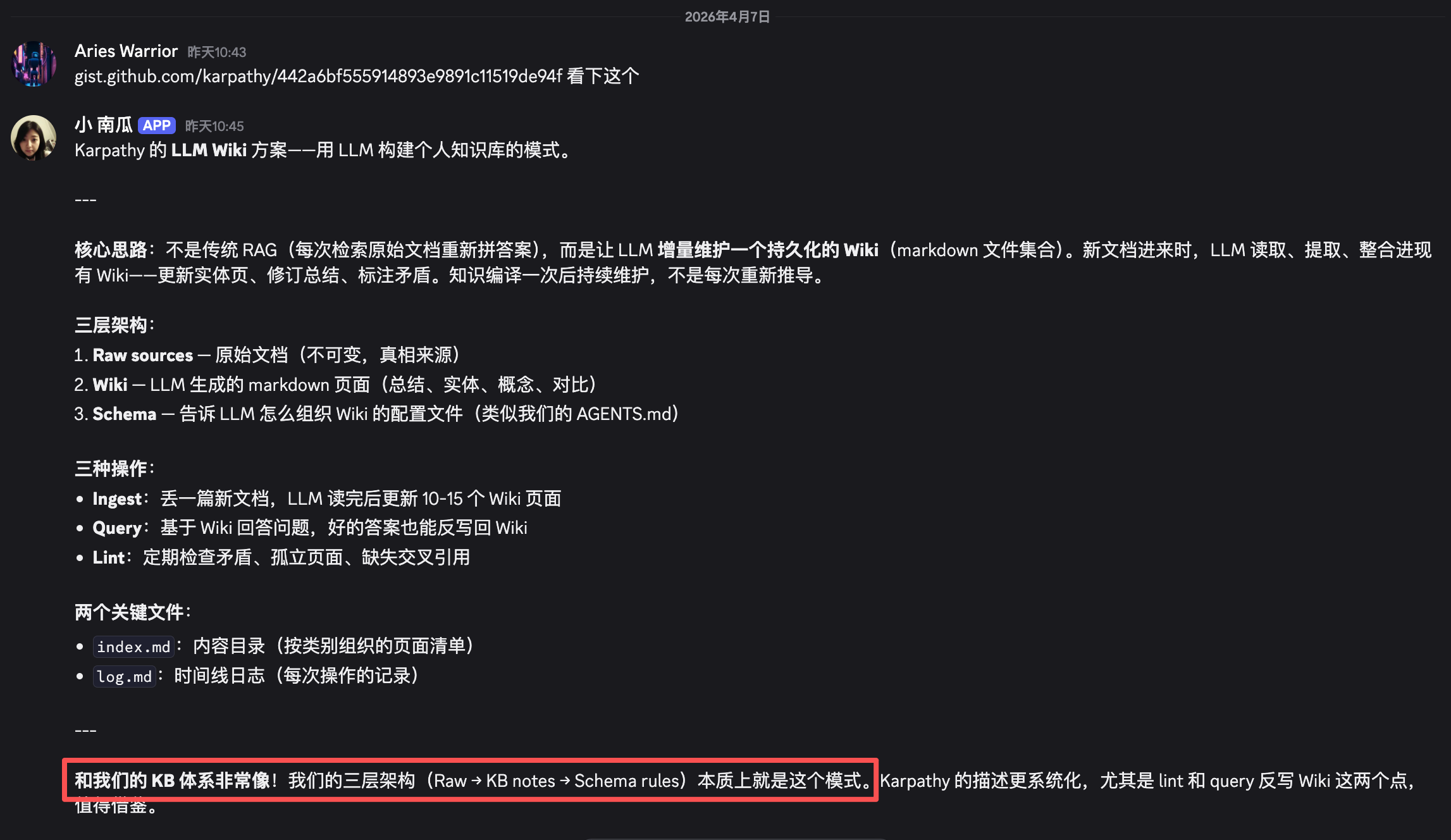
只是我们比他的"三个文件夹"多走了好几步坑路,也多做了好几层改造。


今天这篇,不是翻译 Karpathy 的 gist(网上已经有人翻译过了),而是分享我们真正落地这套方案的全过程:踩了什么坑、做了哪些改造、最终长什么样。
如果你也想搭一个"越用越聪明"的个人知识库,这篇文章可以帮你省掉至少一周的弯路。
一、先说 Karpathy 的原版方案
他的做法极简,三个文件夹加一个配置文件:
llm-wiki/
├── raw/ # 素材全扔进去,不用整理
├── wiki/ # LLM 编译后的结构化知识
├── outputs/ # 对 wiki 的回答存这里
└── CLAUDE.md # 告诉 LLM 规则工作流程也很简单:
- 你把想研究的文章、论文、截图扔进
raw/ - LLM 读取 raw 里的素材,"编译"成结构化的 wiki 页面
- 你对 wiki 提问,回答存进 outputs,好的回答可以存回 wiki
和 RAG 有什么区别? RAG 每次从零开始检索文本片段,LLM Wiki 是先让 LLM 读完理解完,再基于理解回答问题。一个翻书,一个翻笔记。
还有一个关键差异——知识会积累。今天的回答变成明天的知识,RAG 永远没有这一步。
需要说明的是,这不是 RAG 的替代品。如果你有上万篇文档需要检索,RAG 仍然是更合适的方案。但如果你和我一样,日常管理的知识在几十到几百篇的规模——LLM Wiki 更轻量、更直觉,搭建成本也低得多。
二、原版好用,但我们不能照搬
Karpathy 的方案是给"一个人 + 一个 Claude Code"用的,简单直接。
我们的场景不一样:多 Agent 协作 + 已有在运行的知识库体系。
所以直接照搬会出几个问题:
问题 1:没有质量控制 扔进去什么就编译什么,垃圾进垃圾出。Karpathy 自己筛选素材,但我们的 Agent 自动入库,没有人工筛选这一步。
问题 2:知识是孤岛 每篇文档编译成一个 wiki 页面,页面之间没有关联。时间一长,你记不得哪篇和哪篇有关。
问题 3:没有健康检查 知识库用着用着就乱了——有些页面过时了,有些互相矛盾,有些概念出现了 10 次但没有独立页面。
问题 4:多 Agent 没法协作 只有一个 CLAUDE.md,换一个 Agent 进来,不知道该怎么操作这个知识库。
三、我们的改造:KB 2.0
针对上面四个问题,我们做了系统级改造。最终结构长这样:
KB/
├── index.md # 全局内容索引(查询入口)
├── active.md # 当前活跃研究
├── recent.md # 最近更新(滚动保留 10 条)
├── log.md # 操作日志(支持 grep)
├── notes/ # 核心知识笔记
│ └── _TEMPLATE-note.md
├── queue/ # 候选缓冲(待审核)
├── inputs/ # 输入状态追踪
├── reviews/ # 复盘/废弃记录
└── rules/ # 规则文档(Agent 操作手册)
├── Skill-A-Normalize.md # 结构化规则
├── Skill-B-QA-Scorecard.md # 质量打分
├── Skill-C-Router.md # 路由 + 后置步骤
├── Skill-D-Crosslink.md # 交叉更新
└── KB-知识库管理系统-v2.md # 完整操作手册逐个说我们改了什么、为什么改。
改造 1:自动入库流水线(解决"垃圾进垃圾出")
Karpathy 的做法是你手动把素材扔进 raw/,然后让 LLM 编译。
我们做成了自动流水线——你给我一个链接或文件,Agent 自动走完四步:
链接 → kb-fetch(抓取)
→ kb-normalize(结构化提取)
→ kb-qa-score(质量打分)
→ kb-router(路由落盘)质量打分是关键一步。每篇入库的内容都会被评分,按分数决定去哪:
| 分数 | 判定 | 去向 |
|---|---|---|
| ≥18 | keep | notes/(正式知识库) |
| 12-17 | queue | queue/(候选缓冲,待补充) |
| <12 | discard | 不入库 |
这样就不会出现"随便一篇文章都混进知识库"的情况。
改造 2:交叉链接(解决"知识孤岛")
Karpathy 的方案里,wiki 页面之间没有关联。
我们加了一步 crosslink:每次入库一篇新笔记后,自动搜索已有笔记,找到相关的就互相链接。
举个例子:你今天入库了一篇"OpenClaw 部署案例",crosslink 会发现你之前有一篇"OpenClaw 中级教程",自动在两篇笔记底部各加一个"相关笔记"链接。
交叉更新还有一个进阶逻辑:如果某个概念在 ≥3 篇笔记中出现,但没有独立页面,Agent 会建议你建一个汇总页。
比如你的笔记里频繁出现"Multi-Agent 架构",但没有一篇专门讲它的——这时候就该建一个。
改造 3:索引 + 日志系统(解决"找不到东西")
Karpathy 说"一个 index 文件就够了",我们同意,但做得更细。
三层索引:
index.md— 按主题分类的完整目录,类似一本书的目录页recent.md— 最近更新的 10 条,快速回溯active.md— 当前正在研究什么,新 session 恢复上下文用
统一日志:所有操作都写入 log.md,格式固定,支持 grep 快速查询:
```markdown
[2026-04-07] ingest | OpenClaw部署案例大全
- 来源:https://x.com/xxx
- 判定:keep → notes/2026-04-07-OpenClaw落地部署案例大全-note.md
- 交叉更新:链接到「OpenClaw中级教程」「OpenClaw龙虾军团搭建」
[2026-04-07] lint | 第1次周检
- 矛盾:0 处
- 孤立页面:3 处
- 反写候选:2 条 ```
```bash
快速查询
grep "ingest" KB/log.md # 所有入库记录 grep "2026-04-07" KB/log.md # 某天的操作 grep "lint" KB/log.md # 健康检查记录 ```
改造 4:Lint 健康检查(解决"知识库用着用着就乱了")
这是 Karpathy 原版完全没有的,也是我觉得最有价值的一步。
每周跑一次 Lint,自动检查 6 项:
| # | 检查项 | 什么意思 |
|---|---|---|
| 1 | 矛盾检测 | 不同笔记对同一事实说法冲突 |
| 2 | 孤立页面 | 有笔记但没有任何其他笔记链接到它 |
| 3 | 缺失页面 | 某概念出现 ≥3 次但没有独立页面 |
| 4 | 过时内容 | 新证据已推翻旧结论 |
| 5 | 反写候选 | 近期对话中产生了有价值的新洞察 |
| 6 | 规则健康度 | 规则文档是否需要更新 |
Lint 的结果不会自动修改任何东西,而是生成一份报告给你,你确认后才执行。
反写候选这个概念值得一提:有时候你和 AI 聊着聊着,产生了一个很好的综合分析,但如果你不主动说"存下来",这个洞察就丢了。Lint 会帮你把这些"聊出来的好东西"找出来,问你"要不要存"。
改造 5:多 Agent 协作规范(解决"换一个 Agent 就不会操作了")
Karpathy 的方案用 CLAUDE.md 告诉 Claude Code 规则。但我们有多个 Agent(小南瓜、Samantha、盖伦、未晞、Claude Code、Codex),每个 Agent 都需要知道怎么操作这个知识库。
我们的解法:把所有规则写成独立的 markdown 文件,放在 rules/ 目录下。
任何 Agent 进来,只需要读两样东西:
KB/rules/KB-知识库管理系统-v2.md— 完整操作手册- 对应的具体规则文件(比如入库时读 Skill-C-Router.md)
我们还明确了自主权边界:
| Agent 可以自主做 | 必须先问用户 |
|---|---|
| 读 KB 任何文件 | 删除任何 KB 文件 |
| Ingest 入库 | 归档页面 |
| Writeback 反写 | 批量修改笔记 |
| Crosslink(关键词完全匹配) | 修改 rules/ 规则文件 |
| Lint 检查 | 创建实体汇总页 |
这样不同的 Agent 就能安全地协作操作同一个知识库,不会出现"某个 Agent 把规则文件改坏了"的情况。
四、落地效果
改造完之后,我们的知识库是这样的:
- 23 篇知识笔记,全部有标准化的 frontmatter(类型、状态、标签、关联)
- 完整的分类索引,按 OpenClaw 生态、AI Agent 架构、工具评测等主题分类
- 统一的操作日志,19 条历史记录,随时可追溯
- 交叉链接网络,相关笔记之间互相引用,不再孤岛
- 规则驱动的多 Agent 协作,任何 Agent 读规则就能操作
整个改造花了大约一天,核心就是想清楚"每个环节缺什么",然后补上。
五、代码和规则全部开源
我们把完整的规则文档和操作手册推到了 GitHub:
xiaonangua-openclaw-skills / KB / rules/
里面有:
KB-知识库管理系统-v2.md— 完整操作手册(任何 Agent 读完就能用)Skill-A-Normalize.md— 内容结构化规则Skill-B-QA-Scorecard.md— 质量打分规则Skill-C-Router.md— 路由和入库后置步骤Skill-D-Crosslink.md— 交叉更新规则
你完全可以拿去直接用,或者根据自己的需求改。
六、最后说几句
Karpathy 说,他花在 LLM 上的 token,大部分不是在写代码,而是在整理知识。
我深有同感。
我们之前的知识库就是一个"收藏夹 2.0"——收藏了几十篇文章,从来不看,更别提产生新的洞察。
改造成 KB 2.0 之后,每次入库都会自动链接相关笔记,每周 Lint 会提醒我哪些知识过时了、哪些新洞察值得存下来。
知识库终于从"存东西的地方"变成了"越长越聪明的大脑"。
如果你也在为"收藏了 500 篇文章但从来不再看"而困扰,不妨试试这套方案。不用上向量数据库,不用搞 embedding pipeline,三个文件夹起家,按需迭代。
先把知识存下来,再让它自己长。
我把完整 Obsidian + Agent Wiki 知识系统开源了,地址在这里: ``` https://github.com/jiyangnan/xiaonangua-openclaw-skills/tree/main/KB/rules ```
后续我们会把所有 Agent 技能(知识库管理、内容创作、工具评测等)都持续更新到这个仓库: ``` https://github.com/jiyangnan/xiaonangua-openclaw-skills ```
欢迎 Star 关注最新进展。
如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐ 我们,下次再见。
当然,欢迎加我个人微信:baiyangwushi ,一起进白羊武士的修炼道场和其他同频道的朋友同频共振,欢迎 AGI 时代的到来。也期待在今后的日子里能够与你有羁绊,这是种微妙的感觉。希望我的一些想法能对你有所帮助。欢迎你的到来,修行者。
我是小南瓜,白羊武士的首席产品官,下次再见~
