Claude Code泄露之后,AI Agent的护城河到底在哪里
外壳被掀开,并不等于内核被拿走。
这几天,AI 编程圈最热的话题之一,是 Anthropic 的 Claude Code 源码泄露。
很多人的第一反应是:如果 Claude Code 都被看光了,那它是不是就没什么护城河了?再进一步,如果连这种明星产品都能被“拆开看”,那 OpenAI 的 Codex、Cursor、Copilot、Gemini CLI 这些产品,未来到底还拼什么?
我这两天重新梳理了一遍公开资料、官方文档和产品脉络,最后越来越确信一件事:
Claude Code 这次泄露,真正暴露出来的,不只是一个产品的代码,而是整个 AI Agent 赛道正在发生的一次结构性变化。
这场变化的核心不是“谁的模型更强”,而是:
Agent 正在从一个神秘的、封闭的、靠少数团队堆出来的产品,快速变成一套正在被平台化、标准化、商品化的能力。
而一旦这件事成立,未来一两年整个赛道的竞争逻辑,就会彻底改写。
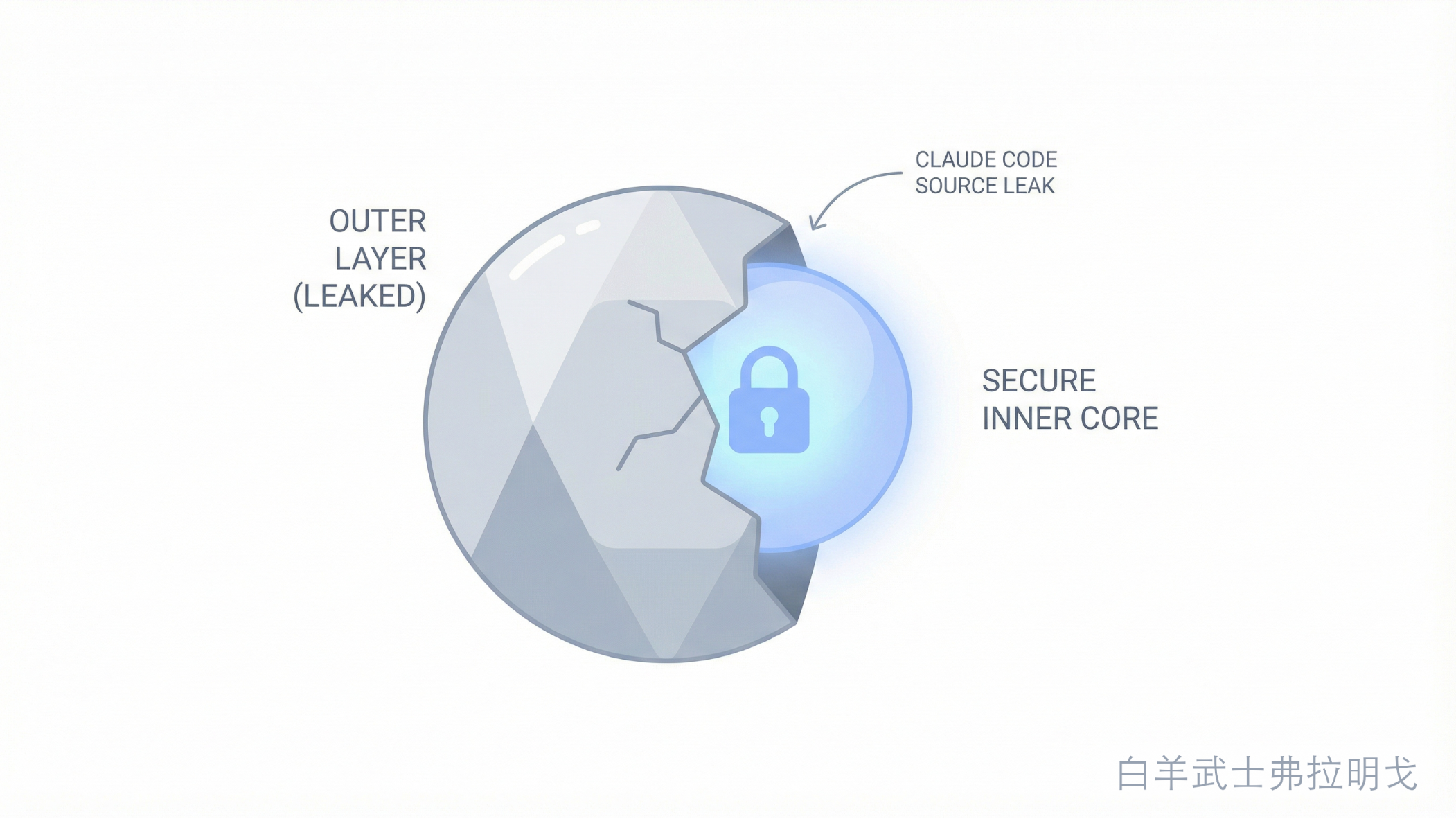
外壳被掀开,并不等于内核被拿走。
一、先把事情说清楚:Claude Code 到底泄露了什么?
先说结论:这次泄露很严重,但没有严重到“Anthropic 被看光了”的程度。
从公开信息看,这次问题的核心,是 Claude Code 某个 npm 包版本误带了 source map,导致外界可以较高保真地还原出 CLI 这一层的大量源代码。换句话说,外界看到的不是一点边角料,而是接近完整的本地客户端 / agent 编排层。
这意味着,大家能看清很多过去只有 Anthropic 自己知道的东西,比如:
- 命令行产品是怎么组织的
- 权限系统怎么设计
- 交互流怎么收口
- 工具调用怎么编排
- provider 适配怎么做
- session、状态、上下文、命令系统怎么串起来
这不是小事。因为在 AI Agent 时代,很多真正值钱的东西并不写在论文里,也不在模型 API 文档里,而是在这些“产品化细节”里。
但与此同时,外界并没有因此拿到 Anthropic 最底层的核心资产。比如:
- Claude 模型权重没有泄露
- 训练数据没有泄露
- 服务端推理系统没有泄露
- 云端基础设施没有泄露
- 账号体系、组织权限、后端特权能力没有泄露
所以这次事情更准确的表述,不是“Claude 被看光了”,而是:
Claude Code 这套产品的本地壳层被看得很透,但 Anthropic 的模型层、云层、账号层仍然是安全的。
二、这件事为什么重要?因为它揭示了 Agent 产品真正的分层
如果把今天主流的 AI Agent 产品拆开看,基本都可以分成四层。
第一层是本地交互层。也就是 CLI、IDE 插件、slash commands、权限弹窗、session 恢复、文件读写、终端调用、工具入口这些。
第二层是模型与 provider 适配层。比如它怎么接 OpenAI、Anthropic、Google,怎么处理不同模型的上下文限制、推理强度、工具能力、fallback 逻辑。
第三层是执行与编排层。包括长任务处理、任务拆分、多 agent 协作、memory、skills、MCP、自动化调度、后台运行等。
第四层是第一方云能力与组织能力。包括账号体系、组织权限、云端沙箱、托管执行环境、审计、风控、策略、私网接入,以及只有官方产品才能调用的后端特权功能。
Claude Code 这次泄露,重伤的是前两层,也波及了第三层的一部分。但第四层,也就是最硬的那层,基本没有被伤到。
这也是为什么,哪怕现在大家已经能更清楚地理解 Claude Code 是怎么做出来的,依然不等于谁都能做出一个“完整版的 Anthropic Claude Code”。
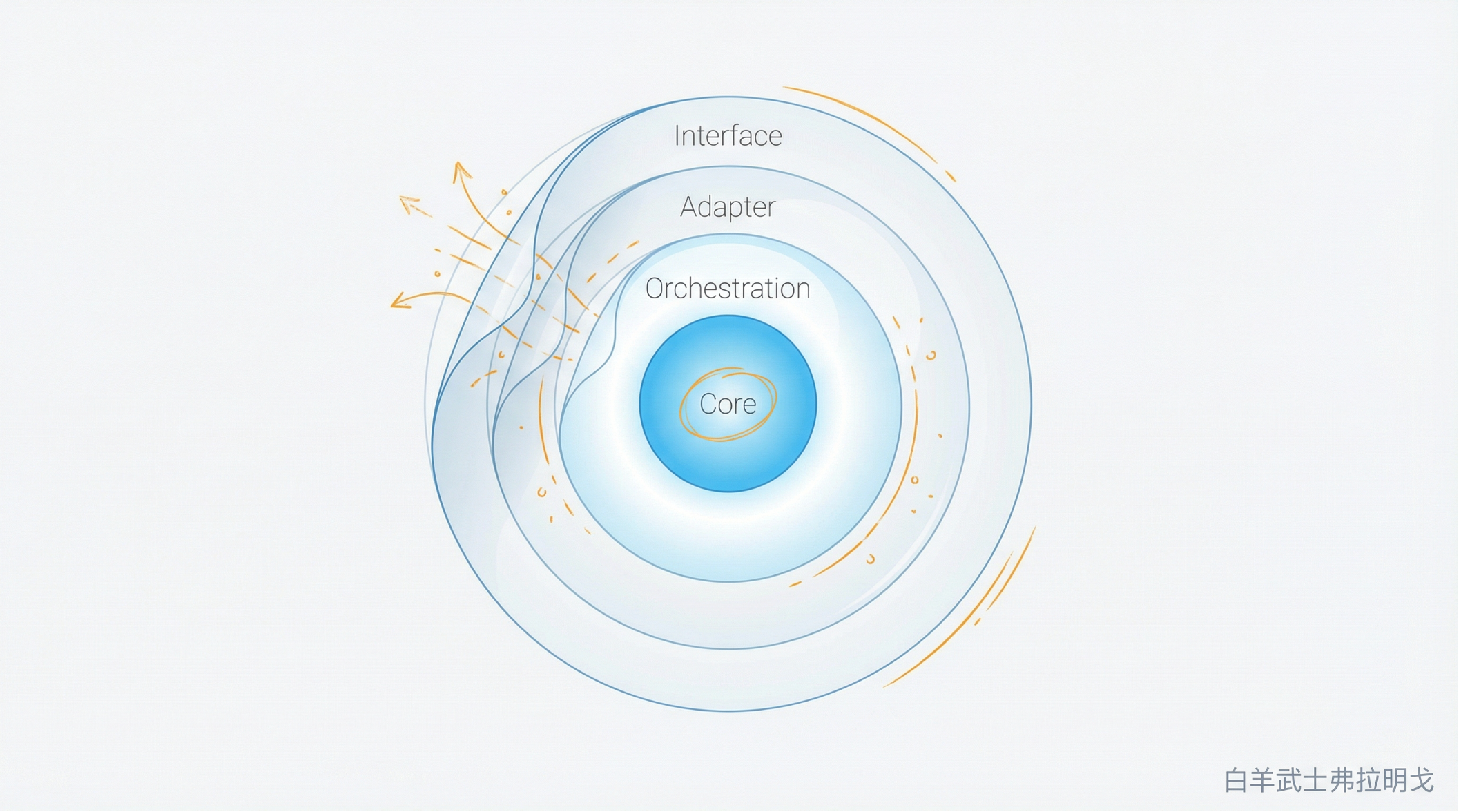
AI Agent 产品并不是一个单体,而是层层嵌套的系统。越往内,越难复制。
三、为什么说真正没被伤到的那一层,依然非常重要?
如果一定要把护城河拆成比例,我会给一个主观判断:
- 被泄露出去的 CLI、本地编排和一部分产品化细节,大约占 25% 到 40%
- 没被伤到的模型、云、账号体系、组织级能力,大约占 60% 到 75%
这不是精确数字,但我觉得这个区间接近现实。
很多人会低估本地壳层的价值。其实它很重要,因为这层包含了大量隐性的产品知识:权限流怎么做、命令系统怎么收敛、上下文怎么组织、失败怎么恢复、工具怎么接、用户怎么被引导。这些东西过去往往要靠团队自己踩很多坑才能积累出来。
所以这次泄露不是“无关痛痒”,而是把 Anthropic 在产品工程上的很多 tacit knowledge,变成了整个行业都能学习的显性知识。
但我仍然不认为这伤到了最深的底座。真正难复制的部分,依然是:
- 模型本身的编码能力和长任务稳定性
- 第一方服务的后端能力
- 组织级账号、权限和策略体系
- 云端执行环境和风控系统
- 分发入口与持续迭代飞轮
换句话说,这次泄露让别人更容易做出“像 Claude Code 的东西”,但仍然很难做出“Anthropic 官方 Claude Code 这个整体体验”。
四、一个看似小的细节,反而最能说明问题:/buddy
最近网上还有一个讨论,说最新的 Claude Code 有了“宠物模式”,也就是 /buddy 这种彩蛋功能,而且似乎只有 Anthropic 自家的模型或官方环境才能触发。
这件事的价值,不在于“宠物模式”本身,而在于它暴露了一个关键信号:
今天很多 AI Agent 的真正差异,已经不再只是模型输出本身,而是第一方产品体系里的特权能力。
像 /buddy 这种功能,表面看只是个有趣的小彩蛋,但背后其实说明了一件事:它不是一个纯本地能力,也不是只靠某个模型名字就能唤出来的功能。它依赖的是 Anthropic 自家的账号体系、组织信息、认证通道和后端接口。
这意味着,即便有人把 Claude Code 的本地客户端抄得很像,甚至复刻得很完整,仍然拿不到 Anthropic 官方产品里的那一层“第一方云特权”。
这也是我为什么认为,这次泄露更像一次严重事故,而不是有意营销。因为如果 Anthropic 真想“半开源”这套东西,完全没必要用这种高风险、负收益的方式。
五、真正的问题不是 Claude Code 会不会受伤,而是 Agent 正在被商品化
相比“Claude Code 还剩多少护城河”,我更关心的是另一件事:
当越来越多的 agent 外壳、CLI、IDE 入口、skills、MCP、自动化框架都逐渐公开、标准化、互相兼容时,AI Agent 这个赛道到底还剩下什么是真正稀缺的?
我的答案是:
“会写代码的 agent”本身,正在快速商品化。
今天几乎所有头部玩家都在往相似的方向走:
- OpenAI 在做 Codex CLI、Codex cloud、IDE、app、automations
- Anthropic 在做 terminal、IDE、browser、CI、多 agent、第三方 provider
- Cursor 在做 background agents、automations、marketplace、self-hosted cloud agents
- GitHub 在把第三方 agent 接进代码托管与 PR 工作流
- Google 一边开源 Gemini CLI,一边把它变成 IDE 里的 agent mode 底座
这意味着,未来行业不太可能长期靠“谁有一个更酷的 coding CLI”来分胜负。因为这一层会越来越像数据库、中间件、前端框架一样,从稀缺能力变成基础设施。
一旦基础设施化开始,竞争就会自然上移。
六、未来真正的护城河,不在“会不会做 agent”,而在“把 agent 接进什么系统”
我现在越来越倾向于一个判断:
未来 AI Agent 的核心护城河,不在 agent 本身,而在 agent 所连接的系统。
这个系统至少包括五样东西。
第一,模型能力。模型仍然重要,尤其是在长任务稳定性、代码理解深度、工具调用可靠性上,强模型依旧有明显优势。
第二,执行环境。是不是有云端沙箱,能不能跑后台任务,能不能安全访问企业资源,能不能进私网,这些会越来越关键。
第三,权限与治理。一个能自动读代码、改代码、跑命令、开 PR、调用外部系统的 agent,如果没有审计、回滚、审批、策略控制,就很难进入真正的大型组织。
第四,组织上下文。代码仓库只是上下文的一部分。真正高价值的上下文,还包括 issue、PR、runbook、事故记录、知识库、团队 ownership 和历史决策。
第五,分发入口。谁能进 IDE,谁能进 GitHub,谁能进企业协作系统,谁就天然更接近工作流主入口。
所以,未来真正值钱的,不是“有一个 agent”,而是:
谁能把模型、权限、上下文、执行环境和组织流程,装配成一个可持续工作的系统。
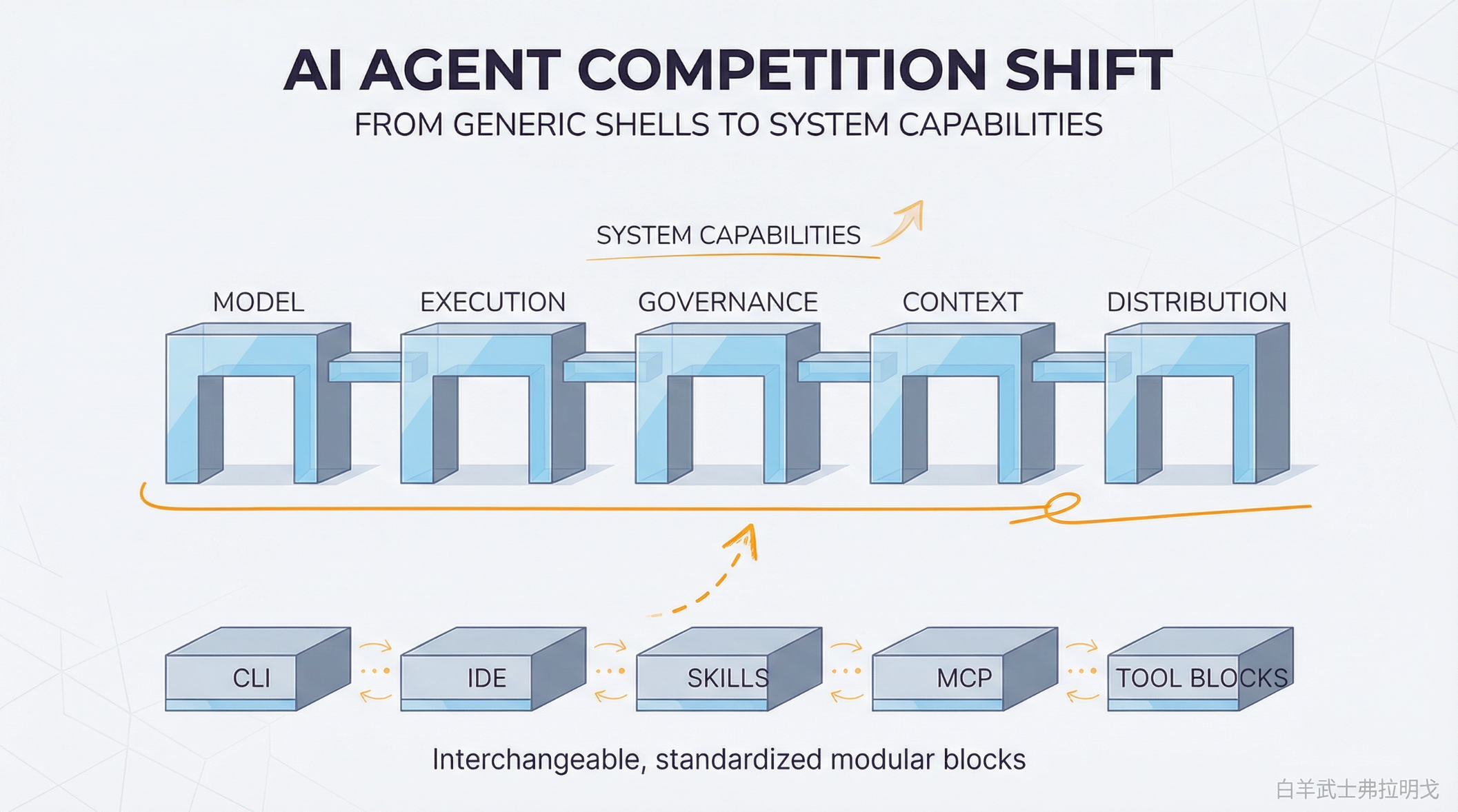
未来竞争的主战场,不会停留在 CLI 和 IDE 外壳,而会继续上移到系统能力。
七、这对创业团队意味着什么?
说到这里,其实结论已经很清楚了:
今天的初创团队当然还有机会,但“再做一个通用 AI Agent 壳”已经不是最好的机会。
为什么?因为这一层正在被平台快速吃掉。
如果你今天的创业计划,本质上是下面这几种之一:
- 再做一个 Claude Code 类似物
- 再做一个多模型 coding CLI
- 再做一个能改文件、跑命令、开 PR 的通用 agent
- 再做一个“更聪明的 IDE agent”
那你面对的不是一个空白市场,而是一片正在被 OpenAI、Anthropic、Google、Cursor、GitHub 同时向下压的基础层。
这类机会不是完全没有,但会越来越难形成独立公司级壁垒。
真正更值得做的,反而是以下几类。
1. 做垂直结果,不做通用入口
客户最终不为“agent 很酷”买单,而为结果买单。
比如:
- 安全漏洞修复
- 测试补全和回归定位
- 大规模迁移
- SQL / 数据变更
- DevOps / incident 响应
- 特定语言或框架的工程自动化
谁能把这些结果做得更稳定,谁就更容易有真实 ROI。
2. 做企业控制面
未来 agent 进企业,最大的阻力不是生成质量,而是治理能力。
这里有大量机会:
- 审批与权限策略
- 多 agent 编排
- 预算与成本路由
- 审计日志与合规留痕
- 沙箱、安全边界、私网接入
- 失败回滚与责任归因
这层一旦站住,比单纯做一个聊天式产品要硬得多。
3. 做上下文基础设施
今天很多 agent 表现不好,不是模型太弱,而是拿到的上下文太差。
谁能把企业内部的代码、文档、工单、知识、流程、ownership 清洗成高质量上下文,谁就可能卡住一个很关键的位置。
4. 做评测、验收和观测
以后企业不会只问“它会不会写代码”,而会问:
- 它写的东西能不能上线?
- 它会不会引入回归?
- 它的风险能不能量化?
- 它失败时能不能定位原因?
- 它比另一个 agent 真的更好吗?
这意味着,AI Agent 赛道里很可能会长出一批“基础设施型公司”,专门做评测、验收、监控、回放、A/B 和风险控制。
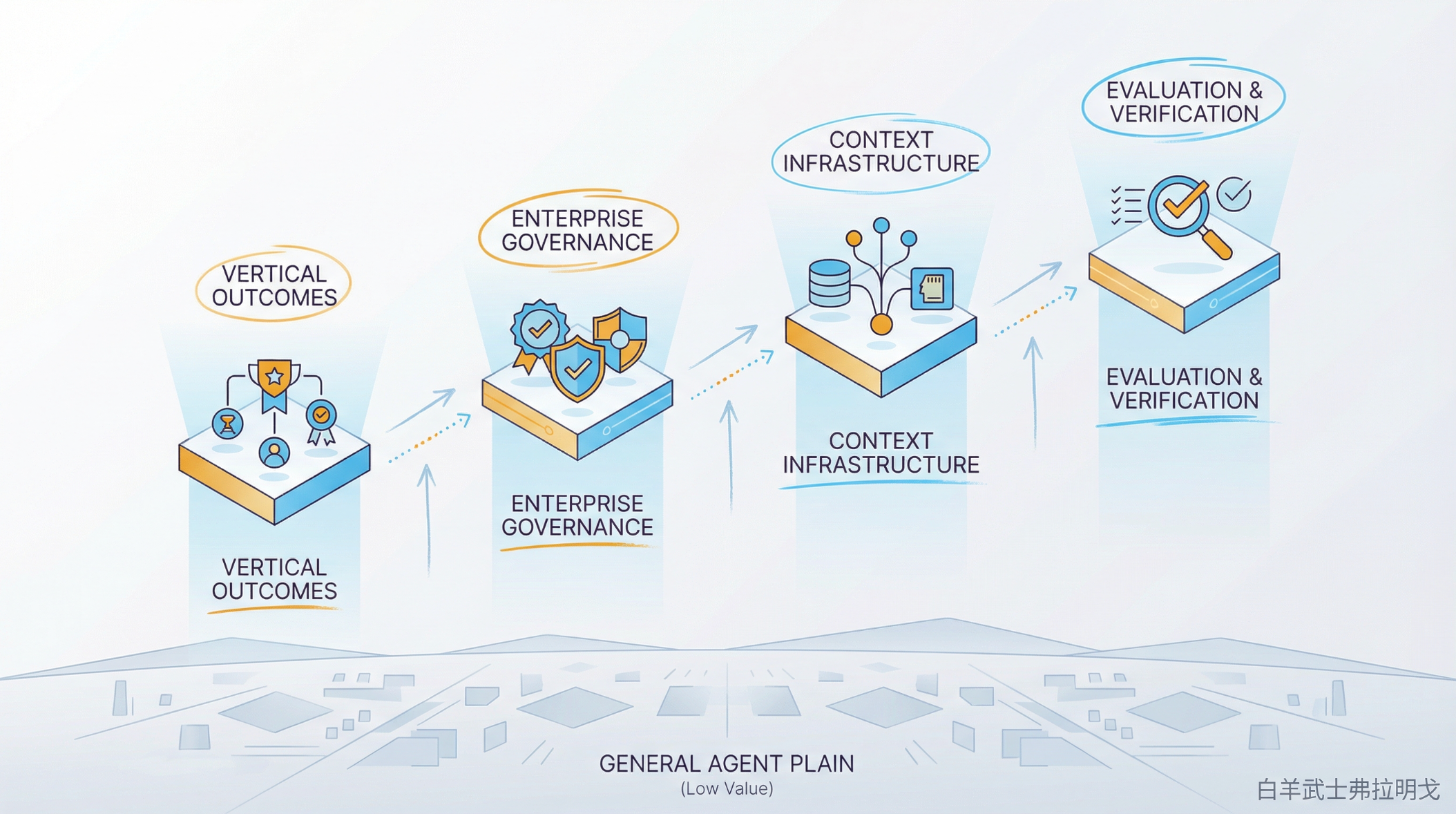
真正值得下注的机会,正在从通用壳层,迁移到结果层、治理层、上下文层和验证层。
八、从更长远看,AI Agent 赛道会变成什么样?
我的判断是,未来一到两年,这个赛道不会出现“一家通吃”的局面,更可能出现一种分层格局:
- GitHub 占住代码托管和企业协作入口
- Cursor 占住高频 IDE 工作台
- OpenAI、Anthropic、Google 占住模型与云 agent 平台
- 大量初创公司围绕垂直结果、治理、上下文、评测和行业化继续生长
也就是说,未来不会只有一个“终极 agent 产品”。相反,Agent 会像云计算时代的各类组件一样,逐渐形成一个完整生态:
- 有模型厂
- 有工作台
- 有调度层
- 有工具市场
- 有企业控制面
- 有垂直场景公司
- 有评测和安全公司
而 Claude Code 的这次泄露,本质上只是提前告诉了我们一件事:
Agent 的表层产品形态,正在迅速失去稀缺性。
真正稀缺的,是那些更深、更重、更靠近组织真实工作流的能力。
九、最后的判断:今天做 AI Agent,应该做什么,不该做什么
如果让我把这篇文章压缩成一句话,那就是:
别把 AI Agent 当成一个产品,而要把它当成一个系统。
不该做的,是把“套一个模型、做一个壳、接几个工具”误以为是公司。该做的,是围绕真实工作流,建立下面这些东西中的至少两到三个:
- 难替代的组织上下文
- 明确可量化的业务结果
- 权限、审计和治理能力
- 私有部署与合规能力
- 持续迭代的数据闭环
- 稳定的分发入口
如果没有这些,所谓“AI Agent 创业”,大概率只是一个容易被平台收编的功能层。
Claude Code 这次泄露,短期看像是一场安全事故;但从更大的产业视角看,它更像一次提醒:
AI Agent 的第一阶段,拼的是谁先把产品做出来;AI Agent 的第二阶段,拼的是谁能把它接进真实世界。
前者决定你能不能做出一个 demo。后者才决定你能不能做成一家公司。
所以,如果你今天还想做 AI Agent 创业,我的建议很简单:
不要再问“我能不能做一个像 Claude Code、Codex、Cursor 那样的产品”;你更应该问的是:
- 我能不能卡住一个真实且高频的工作流?
- 我能不能提供别人替代不了的上下文?
- 我能不能把 agent 的结果变得可验证、可审计、可回滚?
- 我能不能让企业真的敢把这东西接进生产环境?
如果答案只是“我接了一个大模型,做了一个 agent 外壳”,那大概率只是功能。
如果答案是“我把 agent 变成了组织可以依赖的生产系统”,那才有机会成为公司。
而真正的护城河,也只会诞生在后者。
如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐ 我们,下次再见。
当然,欢迎加我个人微信:baiyangwushi,一起进白羊武士的修炼道场群和其他同频道的朋友同频共振,欢迎 AGI 时代的到来。也期待在今后的日子里能够与你有羁绊,这是种微妙的感觉。希望我的一些想法能对你有所帮助。欢迎你的到来,修行者。