成本吃不消?构建本地模型让AI agent成本爆减90%
适用场景: Mac mini M4 16GB 内存 | 降低 API 调用成本
1. 背景与动机
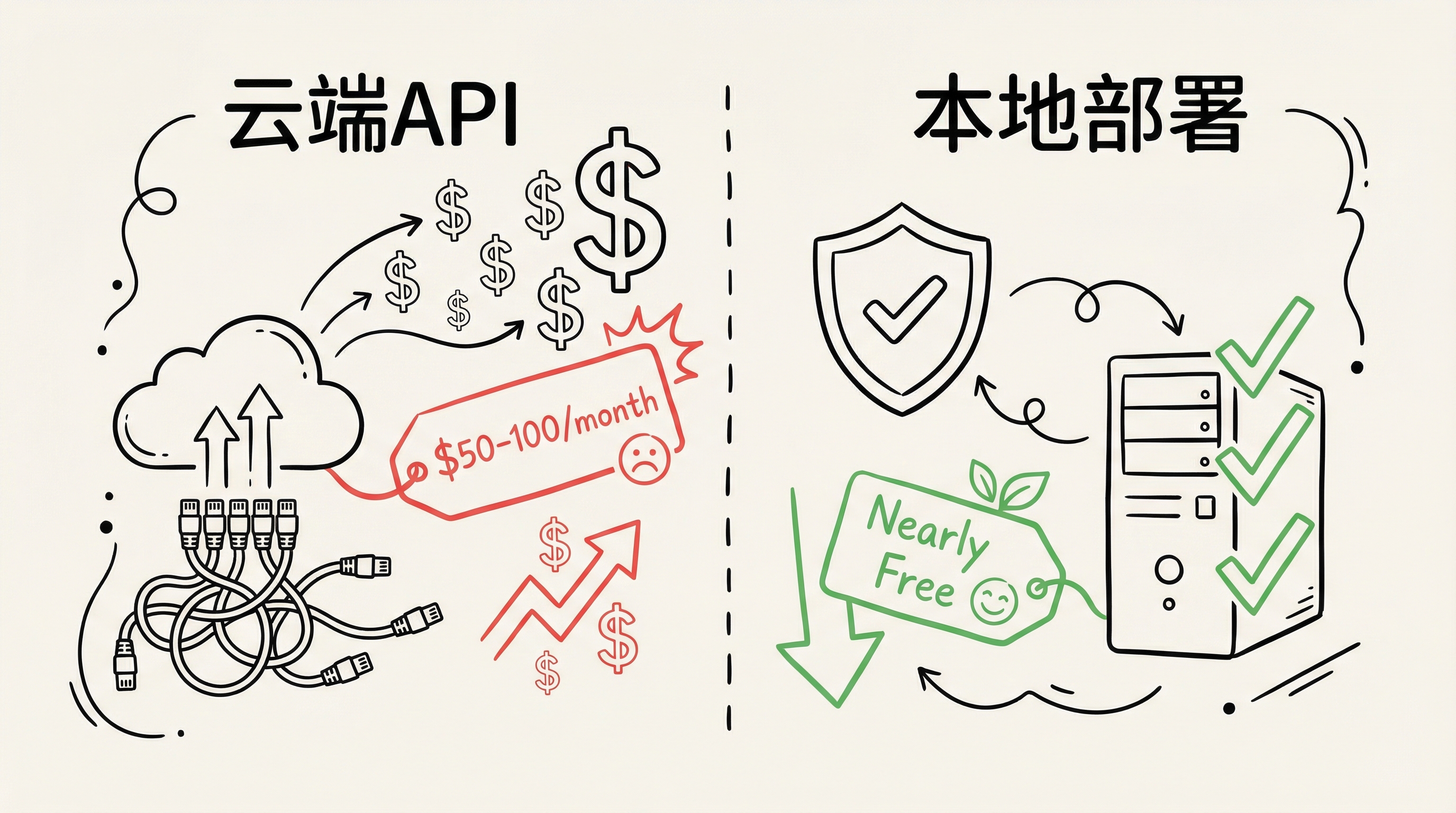
1.1 问题:API 调用成本过高
现状:
- 每月 AI API 调用费用:$50-100+
- 主要使用:GLM-5、MiniMax、Kimi 等云端模型
- 每条消息都需要调用付费 API
痛点:
- 成本累积快
- 依赖网络
- 数据隐私(发送到第三方服务器)
1.2 解决方案:本地部署大模型
优势:
- 成本降低 90%:只有电费成本
- 隐私保护:数据不出本地
- 离线可用:不依赖网络
- 响应更快:本地推理,无网络延迟
劣势:
- 性能略低于 GPT-4 级别
- 需要占用本地内存和硬盘
- 需要技术配置
2. 硬件配置分析
2.1 目标硬件
Mac mini M4
- CPU: Apple M4
- 内存: 16GB 统一内存
- 硬盘: 256GB SSD
2.2 内存限制
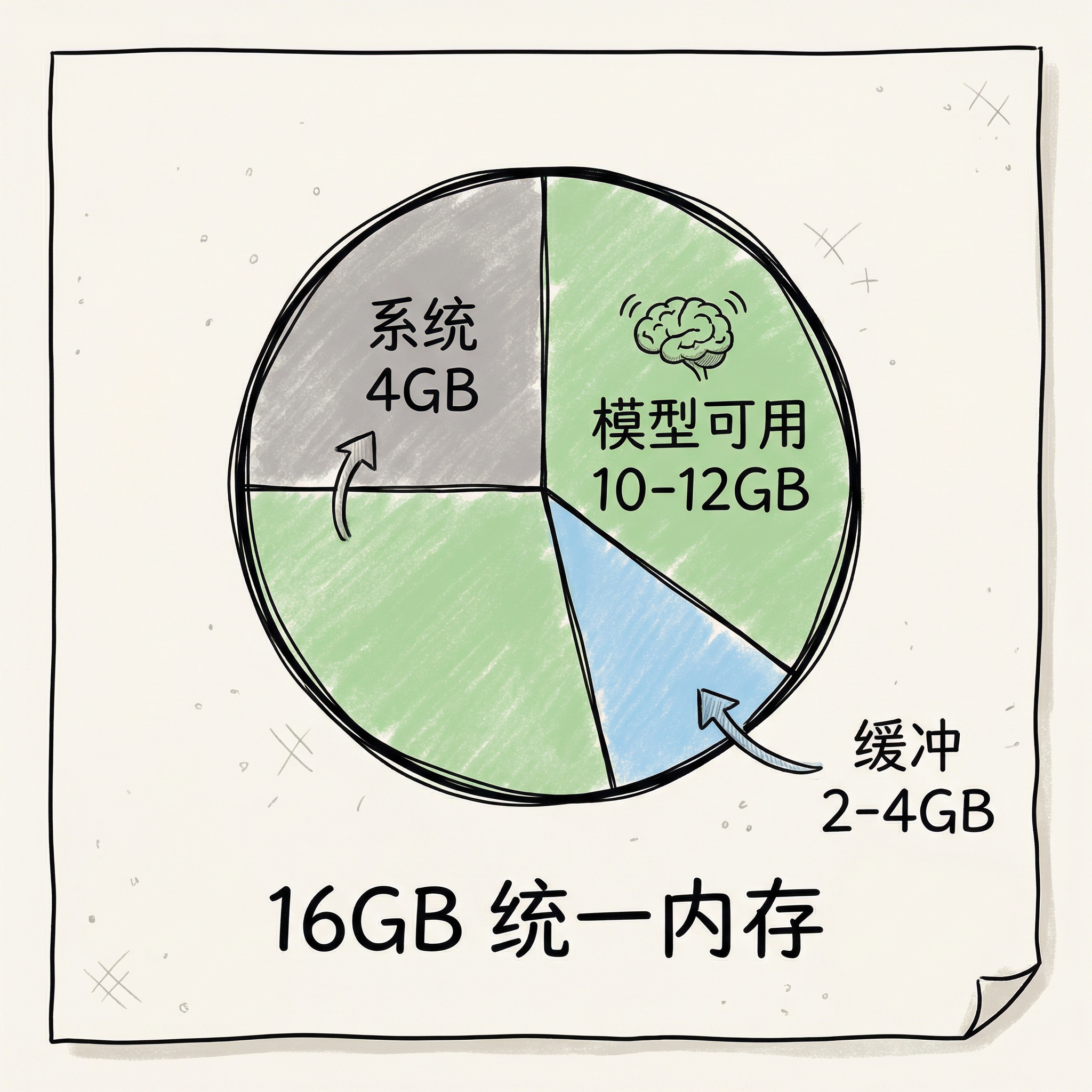
16GB 内存分配:
系统占用: ~4GB
可用给模型: ~10-12GB
缓冲空间: ~2-4GB结论:
- 可以运行 7B 参数模型(占用 7-8GB)
- 可以运行 12-14B 模型(会占满内存)
- 不能运行 30B+ 模型
2.3 硬盘空间
256GB 硬盘分配:
系统: ~30GB
应用程序: ~20GB
3个模型: ~15GB(每个 4-5GB)
剩余空间: ~190GB结论: 硬盘空间充足
3. 开源大模型推荐
3.1 模型对比总表
| 模型 | 参数 | 磁盘 | 内存需求 | 速度 | 中文能力 | 编程能力 | 推理能力 | 最适合 |
|---|---|---|---|---|---|---|---|---|
| Llama 3.2 3B | 3B | 2GB | 3-4GB | 极快 | 一般 | 一般 | 一般 | 快速对话、简单任务 |
| Llama 3.1 8B | 8B | 4.7GB | 8-9GB | 快 | 好 | 好 | 好 | 通用任务、英文优秀 |
| Qwen2.5 7B | 7B | 4.7GB | 7-8GB | 快 | 极好 | 好 | 好 | 中文对话、复杂任务 |
| Qwen2.5 14B | 14B | 9GB | 14-15GB | 中 | 极好 | 极好 | 极好 | 高性能(内存紧张) |
| Qwen2.5-Coder 7B | 7B | 4.7GB | 7-8GB | 快 | 好 | 极好 | 好 | 编程、代码生成 |
| DeepSeek-R1 7B | 7B | 4-5GB | 7-8GB | 中 | 好 | 极好 | 极好 | 复杂推理、数学、逻辑 |
| Phi-4 14B | 14B | 9GB | 14-16GB | 慢 | 好 | 极好 | 极好 | 高性能(占满内存) |
| Mistral 7B | 7B | 4.1GB | 7-8GB | 快 | 一般 | 好 | 好 | 通用、欧洲语言优秀 |
| Gemma2 9B | 9B | 5.5GB | 9-10GB | 中 | 一般 | 好 | 好 | Google出品、平衡性能 |
3.2 最佳推荐组合(16GB 内存)
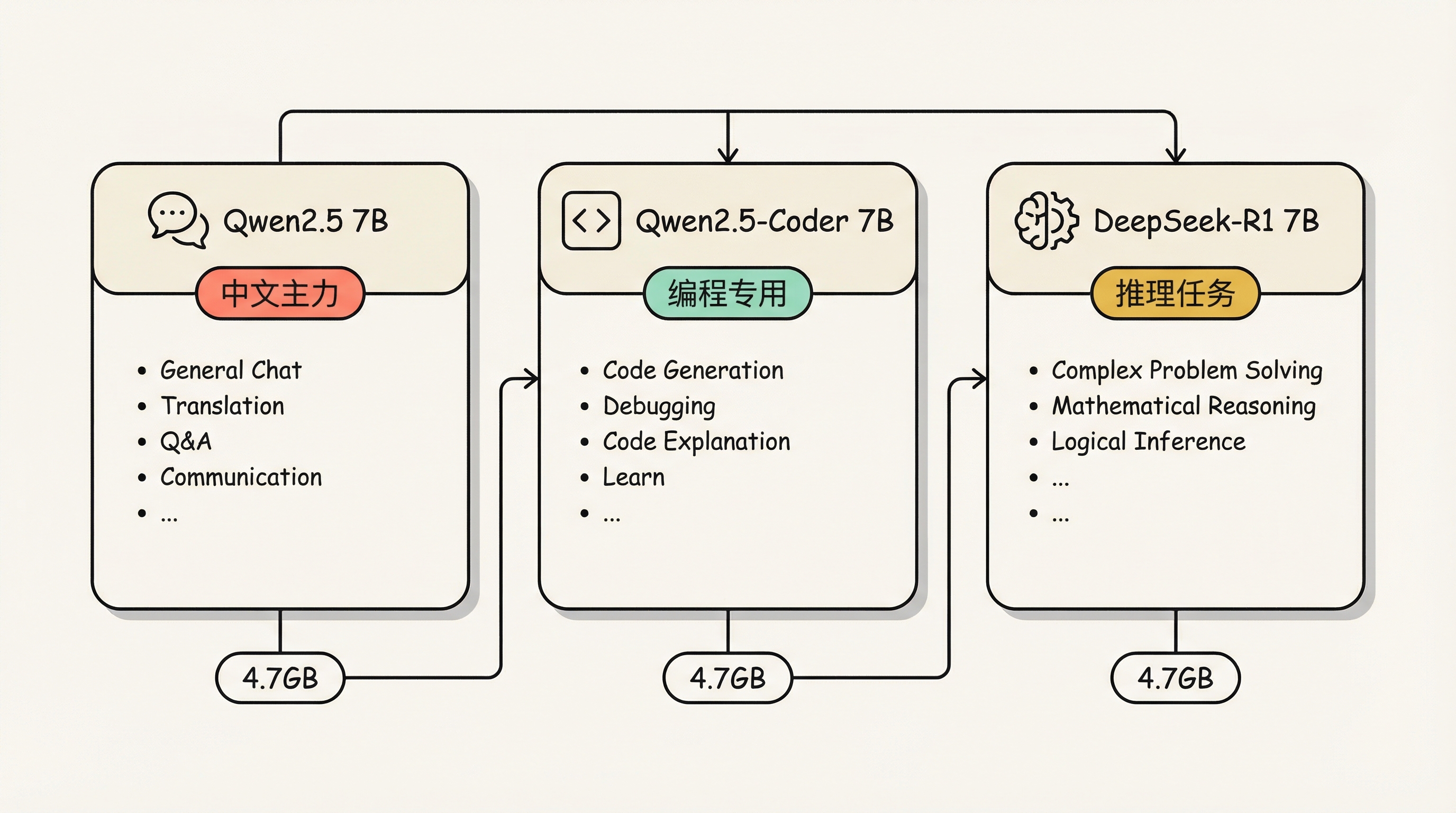
推荐方案:3 个模型组合
1. Qwen2.5 7B - 中文主力模型
2. Qwen2.5-Coder 7B - 编程专用
3. DeepSeek-R1 7B - 复杂推理磁盘占用: ~15GB 内存使用: 一次运行一个,占用 7-8GB
3.3 模型选择原则
根据任务类型选择:
| 任务类型 | 推荐模型 | 原因 |
|---|---|---|
| 日常中文对话 | Qwen2.5 7B | 中文表现最佳 |
| 编程/代码生成 | Qwen2.5-Coder 7B | 专门优化代码能力 |
| 复杂推理/数学 | DeepSeek-R1 7B | 接近 O3 性能 |
| 快速响应 | Llama 3.2 3B | 最小最快 |
| 英文对话 | Llama 3.1 8B | Meta 官方,英文优秀 |
4. Ollama 介绍
4.1 什么是 Ollama?
一句话解释: Ollama = 大模型界的 Docker
核心功能:
- 模型管理:像安装 App 一样安装模型
- 推理引擎:自动优化内存和速度
- API 服务:提供本地 API 接口
4.2 为什么选择 Ollama?
对比其他方案:
| 方案 | 优点 | 缺点 | 适合 |
|---|---|---|---|
| Ollama | 极简、API 友好 | 定制性较低 | 快速部署、日常使用 |
| LM Studio | GUI 界面、可调参数 | 没有 API | 桌面使用、测试 |
| vLLM | 高性能、生产级 | 复杂、需要 Linux | 企业部署 |
| llama.cpp | 轻量、高度可控 | 需要自己编译 | 开发者、极客 |
| HuggingFace | 最全的模型库 | 需要写代码 | 研究、开发 |
结论: Ollama 最适合快速部署和集成到 OpenClaw
4.3 Ollama 工作原理
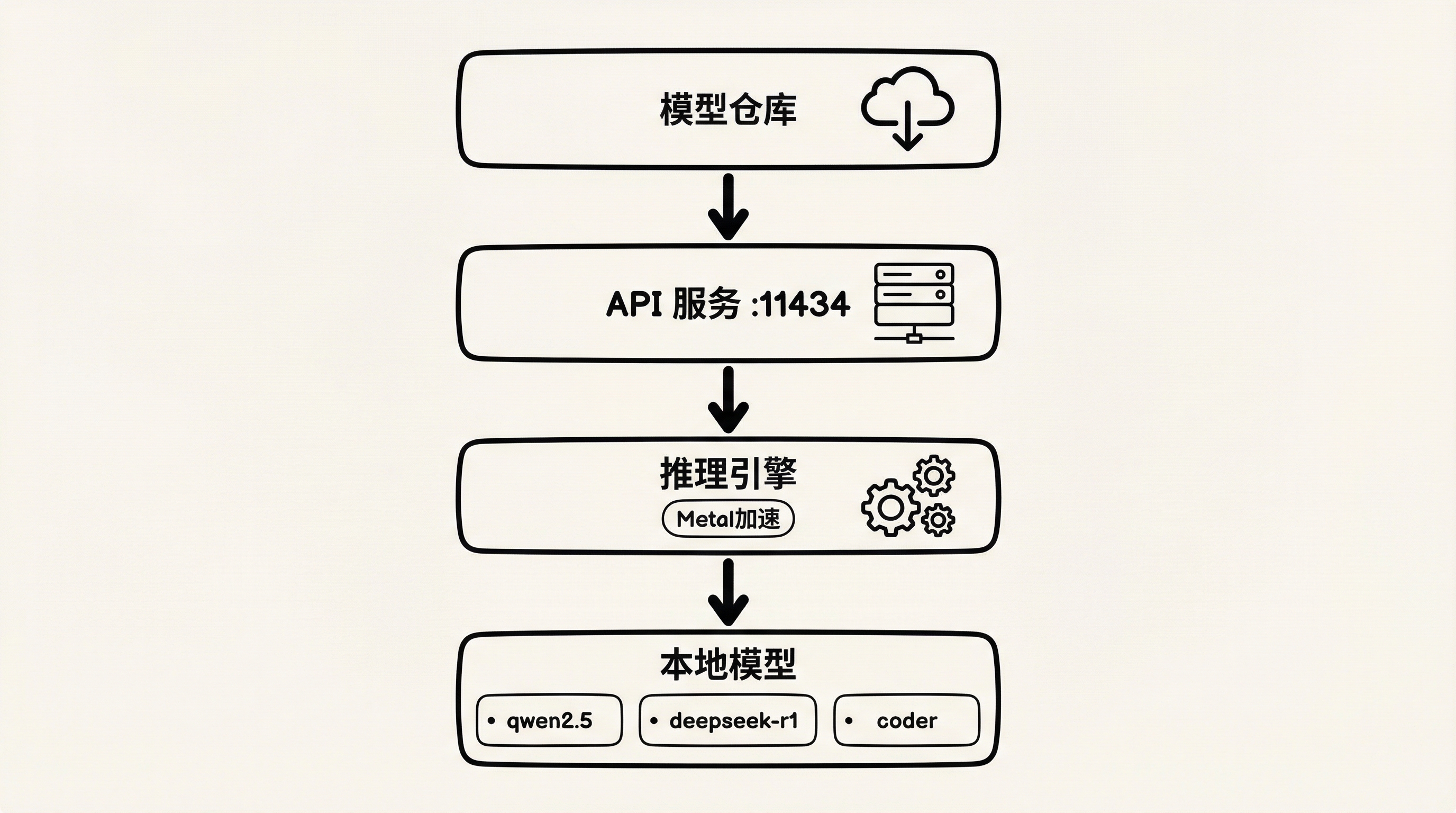
┌─────────────────────────────────────┐
│ Ollama 架构图 │
│ │
│ ┌──────────────┐ ┌─────────────┐ │
│ │ 模型仓库 │ │ API 服务 │ │
│ │ (下载模型) │ │ (:11434) │ │
│ └──────────────┘ └─────────────┘ │
│ ↓ ↓ │
│ ┌──────────────────────────────┐ │
│ │ 推理引擎 │ │
│ │ - 自动量化 │ │
│ │ - 内存管理 │ │
│ │ - Metal 加速 (Apple) │ │
│ └──────────────────────────────┘ │
│ ↓ │
│ ┌─────────────┐ │
│ │ 本地模型 │ │
│ │ - qwen2.5 │ │
│ │ - llama3 │ │
│ └─────────────┘ │
└─────────────────────────────────────┘5. 安装步骤
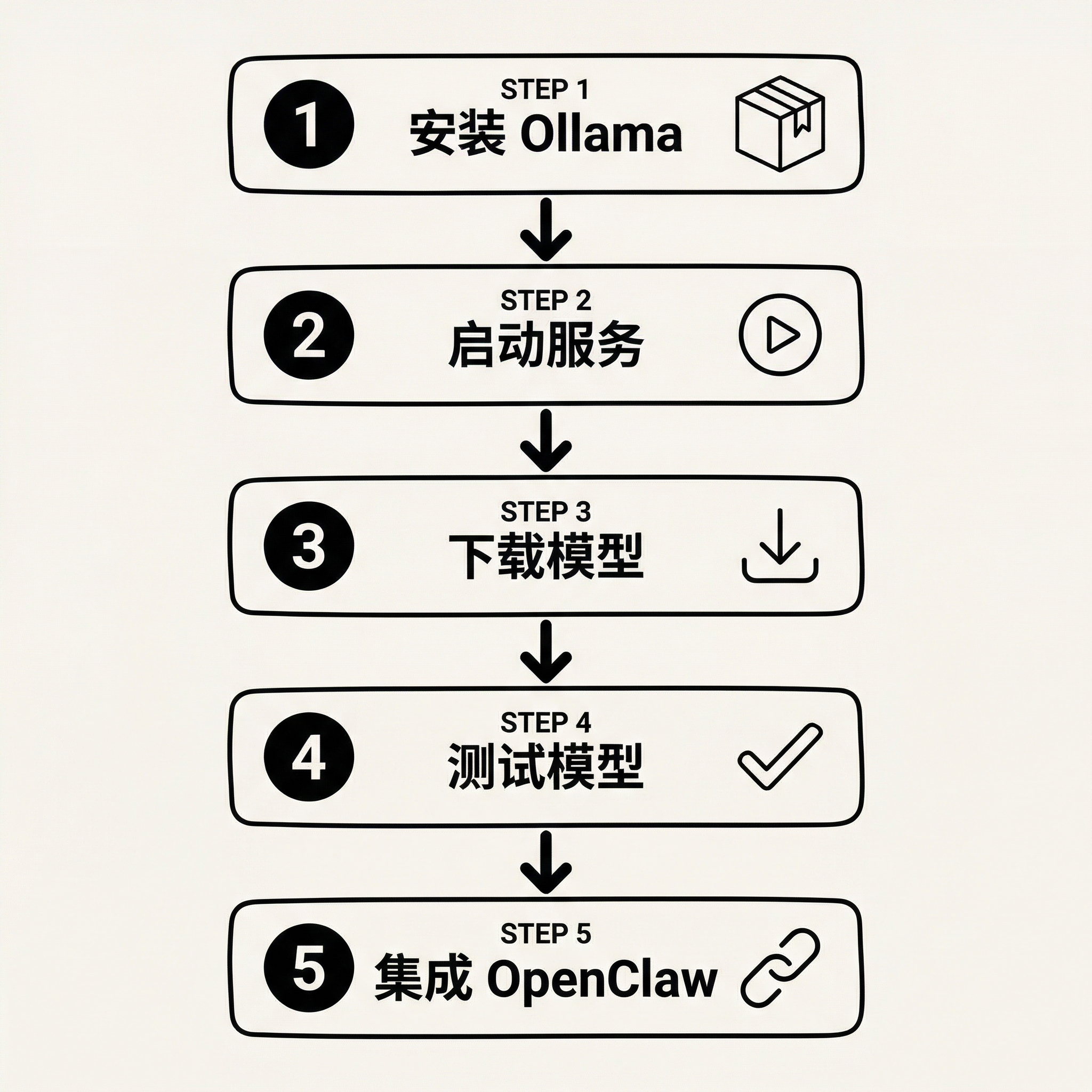
5.1 安装 Ollama
macOS (推荐)
# 方法 1: 使用 Homebrew
brew install ollama
# 方法 2: 官网下载
# 访问 https://ollama.com/download
# 下载 macOS 安装包验证安装
ollama --version
# 输出: ollama version is 0.x.x5.2 启动 Ollama 服务
# 启动服务(后台运行)
ollama serve
# 检查服务状态
curl http://localhost:11434
# 输出: Ollama is running说明:
- 默认端口:
11434 - 默认地址:
http://localhost:11434 - 服务会自动在后台运行
5.3 下载模型
# 下载中文主力模型
ollama pull qwen2.5:7b
# 下载编程专用模型
ollama pull qwen2.5-coder:7b
# 下载推理专用模型
ollama pull deepseek-r1:7b
# (可选) 下载快速模型
ollama pull llama3.2:3b下载时间:
- 每个 7B 模型约 4-5GB
- 根据网速,约 5-15 分钟/个
5.4 测试模型
命令行测试
# 运行模型(进入对话模式)
ollama run qwen2.5:7b
# 对话示例
>>> 你好,请介绍一下你自己
[模型回答...]
>>> 退出
/Ctrl+DAPI 测试
# 使用 curl 测试 API
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "你好",
"stream": false
}'
5.5 常用命令
# 查看已安装模型
ollama list
# 查看模型信息
ollama show qwen2.5:7b
# 删除模型
ollama rm qwen2.5:7b
# 更新模型
ollama pull qwen2.5:7b
# 停止正在运行的模型
ollama stop qwen2.5:7b6. 集成到 OpenClaw
6.1 架构说明
集成后的工作流程:
用户消息
↓
OpenClaw Agent
↓
模型路由策略
├─→ 本地模型 (90% 请求)
│ └─→ Ollama (localhost:11434)
│ └─→ qwen2.5:7b / deepseek-r1:7b
│
└─→ 云端模型 (10% 复杂任务)
└─→ GLM-5 / MiniMax / Kimi6.2 配置步骤
步骤 1: 修改 models.json
文件位置: ~/.openclaw/agents/main/agent/models.json
添加 Ollama provider:
{
"providers": {
"ollama": {
"baseUrl": "http://localhost:11434/v1",
"api": "openai-completions",
"models": [
{
"id": "qwen2.5:7b",
"name": "Qwen 2.5 7B",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 32768,
"maxTokens": 4096
},
{
"id": "qwen2.5-coder:7b",
"name": "Qwen 2.5 Coder 7B",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 32768,
"maxTokens": 4096
},
{
"id": "deepseek-r1:7b",
"name": "DeepSeek R1 7B",
"reasoning": true,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 32768,
"maxTokens": 4096
}
]
}
}
}步骤 2: 修改 openclaw.json
文件位置: ~/.openclaw/openclaw.json
修改主力模型配置:
{
"agents": {
"defaults": {
"model": {
"primary": "ollama/qwen2.5:7b",
"fallbacks": [
"zai/glm-5",
"minimax-cn/MiniMax-M2.5",
"moonshot/kimi-k2.5"
]
},
"models": {
"ollama/qwen2.5:7b": {
"alias": "Qwen"
},
"ollama/deepseek-r1:7b": {
"alias": "DeepSeek"
},
"ollama/qwen2.5-coder:7b": {
"alias": "Qwen-Coder"
}
}
}
}
}步骤 3: 重启 OpenClaw
# 重启 OpenClaw 网关
openclaw gateway restart6.3 验证集成
测试 1: 检查模型列表
# 在 OpenClaw 对话中
/status
# 应该看到包含 ollama/qwen2.5:7b测试 2: 发送测试消息
# 在 Telegram/Discord/飞书 发送
你好,请介绍一下你自己
# 查看回复中的模型标识
# 应该看到: [ollama/qwen2.5:7b]测试 3: 手动切换模型
# 切换到 DeepSeek
/model ollama/deepseek-r1:7b
# 发送推理任务
帮我分析一下这个复杂问题
# 切换回 Qwen
/model ollama/qwen2.5:7b6.4 高级配置(可选)
为不同任务配置不同模型
{
"agents": {
"defaults": {
"model": {
"primary": "ollama/qwen2.5:7b",
"reasoning": "ollama/deepseek-r1:7b",
"coding": "ollama/qwen2.5-coder:7b",
"fallbacks": ["zai/glm-5"]
}
}
}
}说明:
primary: 默认对话模型reasoning: 复杂推理任务自动切换coding: 编程任务自动切换fallbacks: 本地模型失败时的备用
7. 成本对比分析
7.1 月度成本对比
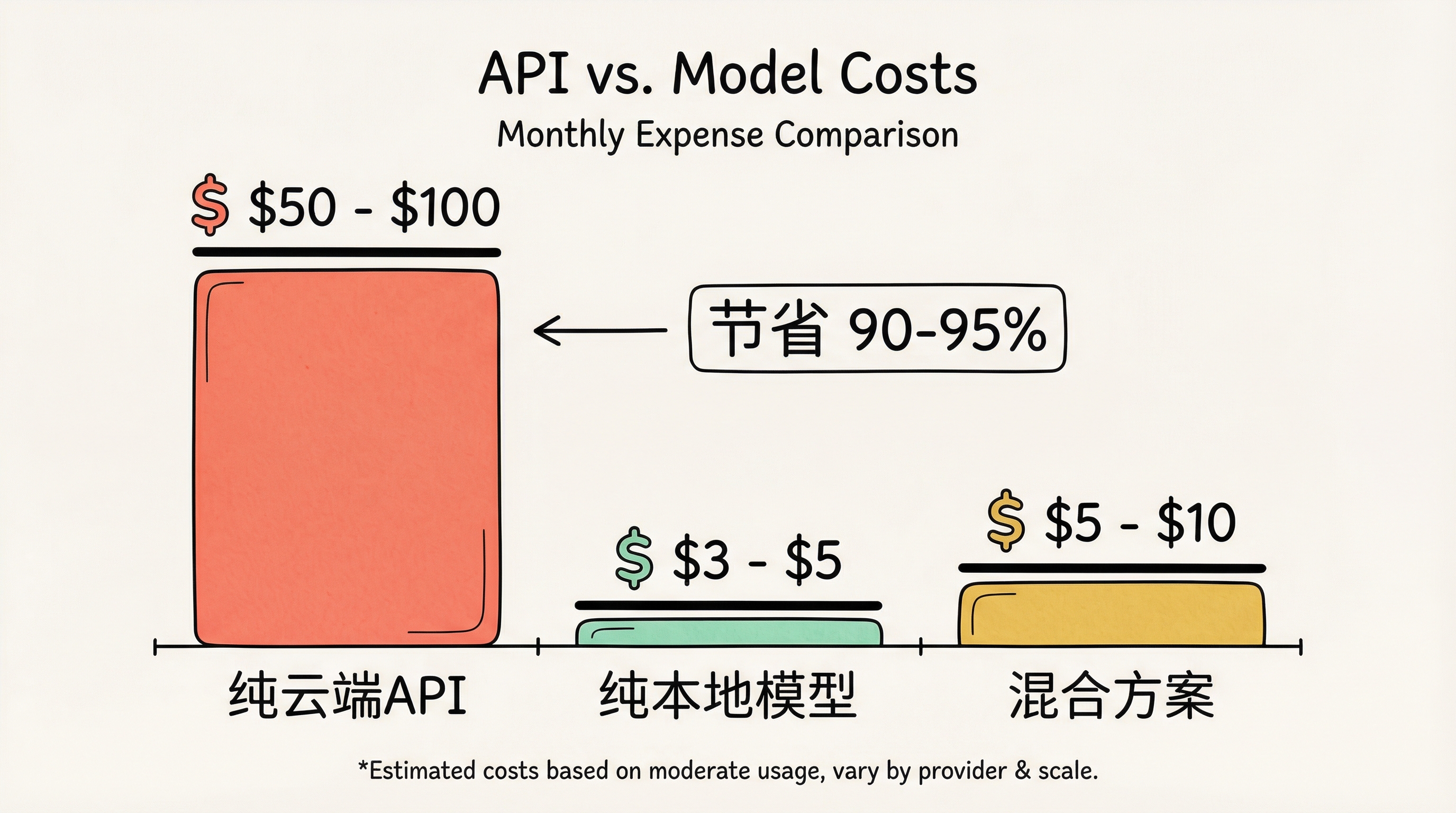
假设场景:
- 每天对话:100 条
- 每条平均:500 tokens
- 月度总 tokens:1.5M tokens
| 方案 | 月成本 | 说明 |
|---|---|---|
| 纯云端 API | $50-100 | GPT-4 / Claude 级别 |
| 纯本地模型 | $3-5 | 电费成本 |
| 混合方案 | $5-10 | 90% 本地 + 10% 云端 |
节省: 90-95%
7.2 性能对比
| 方案 | 速度 | 智能程度 | 成本 |
|---|---|---|---|
| GPT-4 | 中 | 极高 | $$$$ |
| Claude | 快 | 极高 | $$$$ |
| GLM-5 | 快 | 高 | $$$ |
| 本地 Qwen2.5 7B | 极快 | 高 | $ |
| 本地 DeepSeek-R1 7B | 中 | 极高 | $ |
结论:
- 本地模型:性价比最高
- 云端模型:性能最强
7.3 最佳实践建议
推荐策略:
-
主力使用本地模型(90% 场景)
- 日常对话
- 简单任务
- 快速响应需求
-
复杂任务用云端(10% 场景)
- 高质量写作
- 复杂推理
- 专业领域任务
-
根据实时情况自动切换
- OpenClaw 的 fallback 机制
- 本地模型失败自动切换到云端
8. 常见问题
8.1 性能相关
Q: 本地模型比云端慢? A: 不会。本地模型反而更快,因为:
- 没有网络延迟
- Apple Silicon Metal 加速
- 本地内存访问快
Q: 7B 模型够用吗? A: 对于大多数任务够用:
- 日常对话:完全够用
- 简单编程:够用
- 复杂推理:略逊于 GPT-4
- 专业领域:需要更大模型
8.2 内存相关
Q: 同时安装多个模型会占满内存吗? A: 不会。Ollama 一次只加载一个模型到内存:
- 安装 3 个模型:磁盘占 15GB
- 运行 1 个模型:内存占 7-8GB
- 切换时自动卸载旧模型
Q: 16GB 内存够用吗? A: 够用,但要注意:
- 7B 模型:完全没问题
- 12-14B 模型:占满内存,系统会卡
- 30B+ 模型:内存不够
8.3 集成相关
Q: 集成后 OpenClaw 会变慢吗? A: 不会。反而会变快:
- 本地推理更快
- 无网络延迟
- 响应更稳定
Q: 本地模型失败了怎么办? A: OpenClaw 有 fallback 机制:
- 本地模型失败 → 自动切换到云端模型
- 保证服务不中断
Q: 可以随时切换回云端模型吗? A: 可以。三种方式:
- 修改配置文件重启
- 使用
/model命令临时切换 - 设置 fallback 自动切换
8.4 模型选择
Q: Qwen2.5 和 Llama 3 选哪个? A: 看需求:
- 中文为主 → Qwen2.5 7B
- 英文为主 → Llama 3.1 8B
- 都要 → 都装(反正磁盘够)
Q: DeepSeek-R1 值得装吗? A: 值得,如果需要:
- 复杂推理
- 数学计算
- 逻辑分析
- 只是简单对话 → 不需要
Q: Coder 模型有必要吗? A: 看用途:
- 经常写代码 → 值得装
- 偶尔编程 → 用通用模型也够
9. 总结
9.1 核心要点
-
Ollama 是最佳选择 — 极简安装、API 友好、易于集成
-
推荐 3 模型组合 — Qwen2.5 7B(中文主力)+ Qwen2.5-Coder 7B(编程)+ DeepSeek-R1 7B(推理)
-
成本节省 90% — 本地模型免费,只在复杂任务用云端
-
集成简单 — 修改 2 个配置文件,重启 OpenClaw,立即生效
9.2 下一步行动
立即开始:
# 1. 安装 Ollama
brew install ollama
# 2. 启动服务
ollama serve
# 3. 下载模型
ollama pull qwen2.5:7b
# 4. 测试
ollama run qwen2.5:7b
# 5. 修改 OpenClaw 配置
# 6. 重启 OpenClaw
# 7. 享受低成本 AI附录:快速参考卡片
常用命令
# 安装
brew install ollama
# 启动
ollama serve
# 下载
ollama pull qwen2.5:7b
# 运行
ollama run qwen2.5:7b
# 列表
ollama list
# 删除
ollama rm qwen2.5:7b
# API
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "你好"
}'
配置文件
- models.json:
~/.openclaw/agents/main/agent/models.json - openclaw.json:
~/.openclaw/openclaw.json
端口
- Ollama API:
http://localhost:11434 - OpenClaw Gateway:
http://localhost:18789
如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标 我们,下次再见。
当然,欢迎加我个人微信:baiyangwushi ,一起进群和其他同频道的朋友同频共振,欢迎 AGI 时代的到来。也期待在今后的日子里能够与你有羁绊,这是种微妙的感觉。希望我的一些想法能对你有所帮助。